Train – Test Split Code
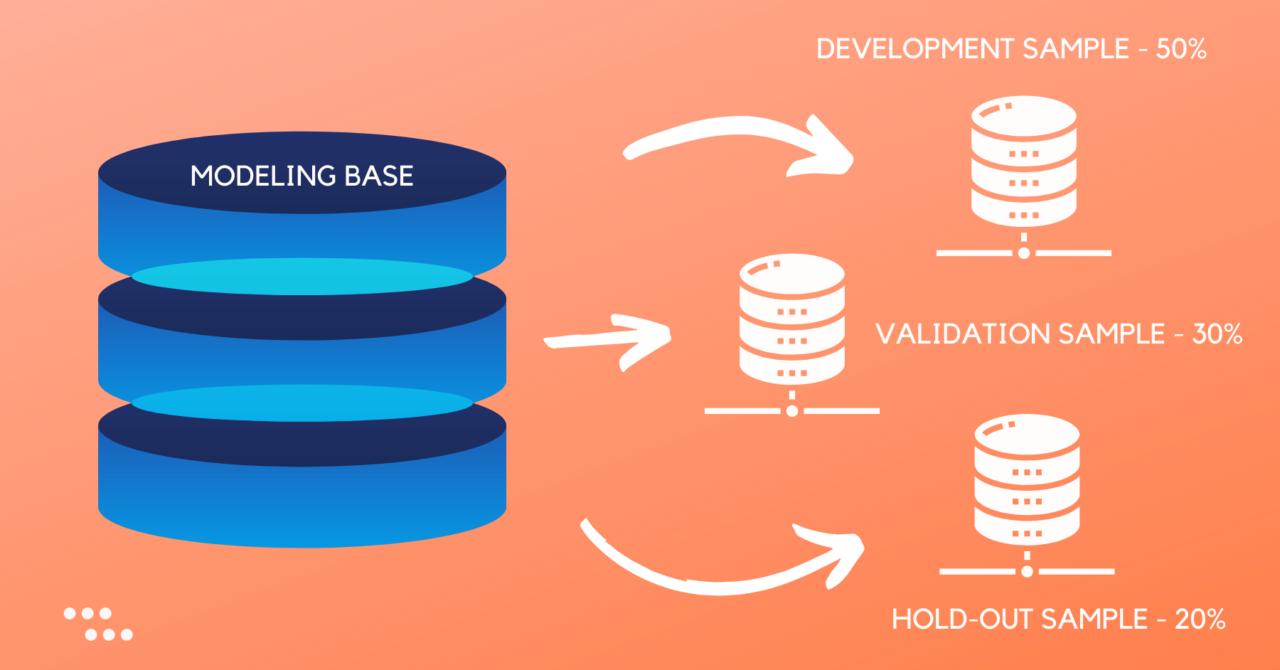
In the previous blog, we learned that Train/Test is the method used to evaluate supervised machine learning models. Let us see how to split the data in training and testing set in Python & R. The Python and R code below is to split the given data into development, validation, and hold-out sample in 50:30:20 proportions.
R Code to split the data
# R code to import the data > LR_DF <- read.csv("LR_DF.csv") > dim(LR_DF) [1] 20000 10 # Code to split the data into development, validation and hold-out sample > random <- runif(nrow(LR_DF), 0, 1) > dev <- LR_DF[which(random <= 0.5),] > val <- LR_DF[which(random > 0.5 & random <= 0.8 ),] > holdout <- LR_DF[which(random > 0.8),] > c(nrow(dev), nrow(val), nrow(holdout)) [1] 9988 5957 4055
Python Code to split the data
# Python code to import the data import pandas as pd LR_DF = pd.read_csv("LR_DF.csv") LR_DF.shape (20000, 10) # Code to split the data into development, validation and hold-out sample import numpy as np dev, val, holdout = np.split( LR_DF.sample(frac=1, random_state=1212), [int(.5*len(LR_DF)), int(.8*len(LR_DF))] ) (len(dev), len(val), len(holdout)) (10000, 6000, 4000)
<<< previous blog | next blog >>>
Logistic Regression blog series home
Recent Comments