Introduction to Classification Tree
Classification Tree is a Supervised Machine Learning Technique. It is used when data has two or more classes and the objective is to find the defining characteristics for each of the classes. Pros of this technique are:
- it is very simple & easy to understand
- the output is in the form of a hierarchical tree thereby making interpretation very easy
Classification Tree Retail Banking Case-Study
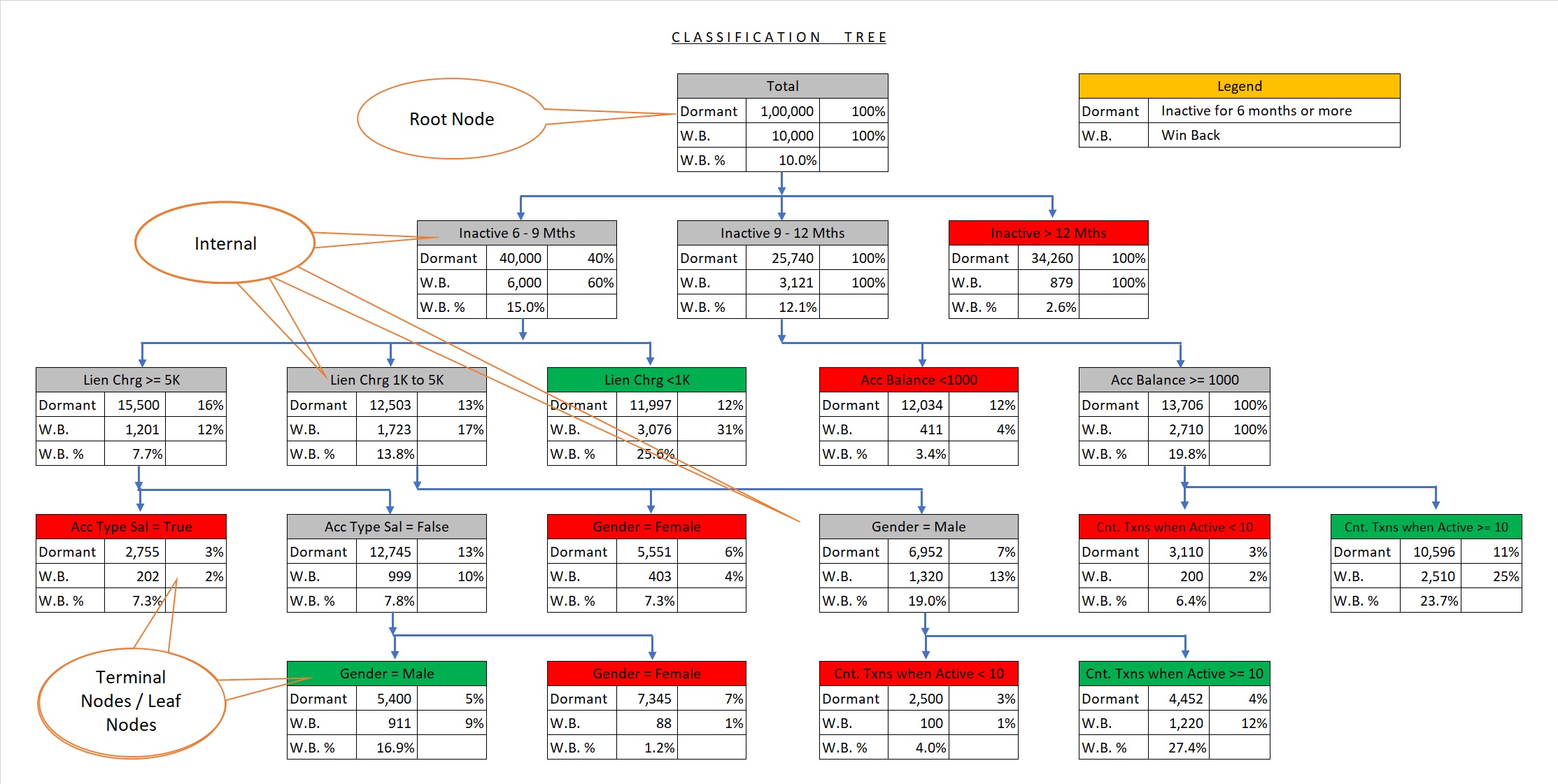
In our previous blog on Retail Banking Case-Study, we had discussed the application of the Classification Tree technique in classifying the Win-Bank customers. The classification tree output is shown below for quick reference.

Challenges in building Classification Tree
For a while, assume you have to build the Classification Tree based on your business judgment and numerical skills without using any Machine Learning Algorithm. The steps you would follow will be an iterative process:
- Identifying Splitting Criteria – Selecting an attribute such that it best separates the classes. The real challenge is in selecting one attribute out of the many available attributes for splitting the starting data, i.e. Root Node data into child nodes. The decision to select a particular attribute out of the many other competing predictor variables would involve lots of intellectually stimulating analysis happening in the mind, on excel, paper, and conversations with associates/colleagues.
- No. of Child Nodes – Having decided the attribute, the next task will be to decide how many child nodes to create from the parent node.
- Repeating Step 1 & 2 – Having split the Root Node into the child node, we may wish to further split the child node. This will involve repeating processes 1 & 2 for the child nodes.
- Stopping Condition – How many iterations of steps 1 & 2 should we repeat? It would depend on one’s judgment. You may want to continue iterating steps 1 & 2 till you feel that it merits to further split the nodes into sub-nodes.
Classification Tree Algorithms
The key feature that a classification tree algorithm provides are:
- Splitting Criteria – Based on the criteria used to find the next best split, there are three popular classification tree algorithms. The algorithms are CHAID, CART, & C5.0.
- CHAID makes use of CHI-SQ Statistics as the measure of association for finding the best splitting criterion
- CART makes use of Gini as a measure of impurity to identify the best variable for splitting the node
- C5.0 makes use of entropy gain (information gain) for the next best split in building the classification tree.
- Binary Split / Multi-way split – CART & C5.0 gives you binary split whereas CHAID can split in two or more than two child nodes.
- Stopping Condition – The depth of the tree and number of terminal nodes (leaf nodes) can be controlled by having stopping rules like max-depth, the minimum number of records in terminal nodes, and min number of records required for a node to further split.
- Pruning – The classification tree techniques also support pruning to remove unwanted terminal nodes.
Sign-Off Note
You can find the Classification Tree Model Development Videos on our YouTube Channel.
- Classification Tree – CART, CHAID, C5.0 in Python
- Classification Tree Model on Personal Loans Cross-Sell Data (Unbalanced Data) using Python
- Retail Banking Case Study
Thank you !!!
Hi, Could please let me know where the next article is. thanks
Dear Praveen,
You can find the Classification Tree Models on our YouTube Channel
Video Links
https://youtu.be/Sbi9DI5Ag1g – This video covers Classification Tree – CART, CHAID, C5.0 in Python
https://youtu.be/1j6X7_WZ0Nw – This Video covers the Classification Tree Model on Personal Loans Cross-Sell Data (Unbalanced Data) using Python
https://youtu.be/JE1Z1zVzGTY – This Video covers the Retail Banking Case Study
Regards.