Information Value and Weight of Evidence (WoE) are the two most used concepts in Logistic Regression for variable selection and variable transformation respectively. Information Value helps quantify the predictive power of a variable in separating the Good Customers from the Bad Customers. Whereas, WoE is used for the transformation of categorical variables to continuous.
Pre-reads: Information Value and Variable Transformation
Understanding WoE Calculations
WoE is calculated by taking the natural logarithm (log to base e) of the ratio of %Good by %Bad.
Weight of Evidence Formula
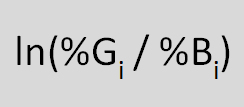
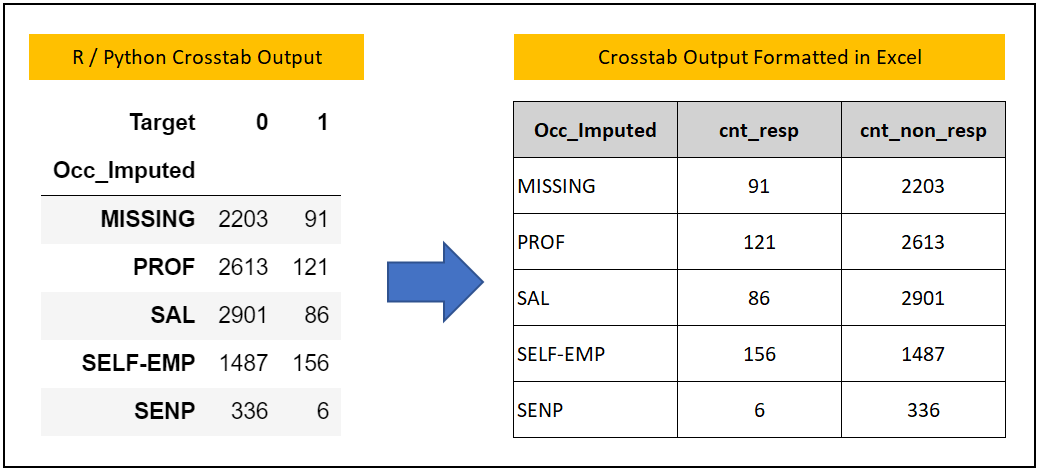
The table below shows the Weight of Evidence calculations for the Occupation field. I will walk you through step-by-step calculations to compute WoE.
| Occ_Imputed | cnt_resp | cnt_non_resp | pct_resp | pct_non_resp | WOE |
|---|---|---|---|---|---|
| MISSING | 91 | 2203 | 0.197826 | 0.230922 | -0.154694 |
| PROF | 121 | 2613 | 0.263043 | 0.273899 | -0.040441 |
| SAL | 86 | 2901 | 0.186957 | 0.304088 | -0.486441 |
| SELF-EMP | 156 | 1487 | 0.339130 | 0.155870 | 0.777362 |
| SENP | 6 | 336 | 0.013043 | 0.035220 | -0.993329 |
Step 1: Get the frequency count of the dependent variable class by the independent variable. This step will give the first three columns of the above table.
- Occ_Imputed: Independent Varible.
- cnt_resp: Count of Responders, i.e Target = 1
- cnt_non_resp: Count of Non-Responders i.e Target = 0
# Crosstab code in Python pd.crosstab(dev["Occ_Imputed"], dev["Target"]) # Crosstab code in R table(dev$Occ_Imputed, dev$Target) # Note - The Development Sample of R and Python is not exactly the same. # As such, you can expect some difference in R and Python crosstab output.
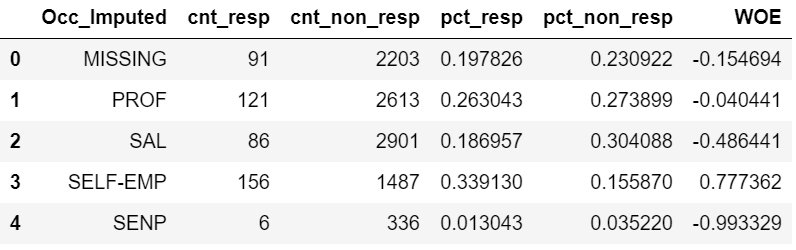
Step 2: Convert the count values into proportions. The formula is count responders divided by total responders and likewise count non-responders divided by total non-responders.
| Occ_Imputed | cnt_resp | cnt_non_resp | pct_resp | pct_non_resp |
|---|---|---|---|---|
| MISSING | 91 | 2203 | 91/460 = 0.198 | 2203/9540 = 0.231 |
| PROF | 121 | 2613 | 121/460 = 0.263 | 2613/9540 = 0.274 |
| SAL | 86 | 2901 | 86/140 = 0.187 | 2901/9540 = 0.304 |
| SELF-EMP | 156 | 1487 | 156/140 – 0.339 | 1487/9540 = 0.156 |
| SENP | 6 | 336 | 6/140 = 0.013 | 336/9540 = 0.035 |
| Total | 460 | 9540 |
Step 3: Calculate WoE by taking the natural log of the ratio of Responders proportion divided by Non-Responders.
| Occ_Imputed | cnt_resp | cnt_non_resp | pct_resp | pct_non_resp | WOE |
|---|---|---|---|---|---|
| MISSING | 91 | 2203 | 0.198 | 0.231 | ln(0.198/0.231) = -0.155 |
| PROF | 121 | 2613 | 0.263 | 0.274 | -0.040441 |
| SAL | 86 | 2901 | 0.187 | 0.304 | -0.486441 |
| SELF-EMP | 156 | 1487 | 0.339 | 0.156 | 0.777362 |
| SENP | 6 | 336 | 0.013 | 0.035 | -0.993329 |
Python code to compute WoE
We have automated the above WoE calculation in the k2_iv_woe_function.py file. You can download the k2_iv_woe_function.py file from Github.
exec(open("k2_iv_woe_function.py").read()) woe_table = woe(df=dev, target="Target",var="Occ_Imputed", bins = 10, fill_na = True) woe_table
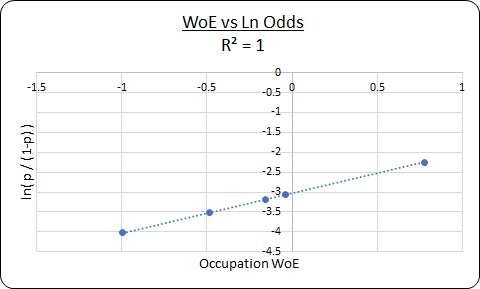
Application of WoE for Variable Transformation
The WoE can be used to transform Categorical Variable to Numerical. You do this by substituting each category by their respective WoE value. The benefit of WoE transformation is that the WoE transformed variable has a linear relationship with the log odds. To understand it better, execute the below code and see its Ln Odds Visualization chart.
Benefits of using WoE in Logistic Regression
1. Does away with One-Hot Encoding: Some of the machine learning packages do not take the categorical variables directly. You have to convert the categorical variables into a dummy 1-0 matrix also called one-hot encoding. If there are many categories in the categorical variable then, it would add many columns in the dataset. We can do away with the one-hot encoding by using the WoE step.
2. Only One Beta Coefficient: A categorical variable with “n” categories will result in having “n-1” beta coefficients in the model. However, converting a categorical variable to its WoE equivalent will have only one beta coefficient thereby simplifying the model equation.
<<< previous blog | next blog >>>
Logistic Regression blog series home
Recent Comments